| 1 | import requests |
| 2 | import pandas as pd |
| 3 | import time |
| 4 | import logging |
| 5 | from pathlib import Path |
| 6 | import re |
| 7 | from datetime import datetime, timedelta |
| 8 | |
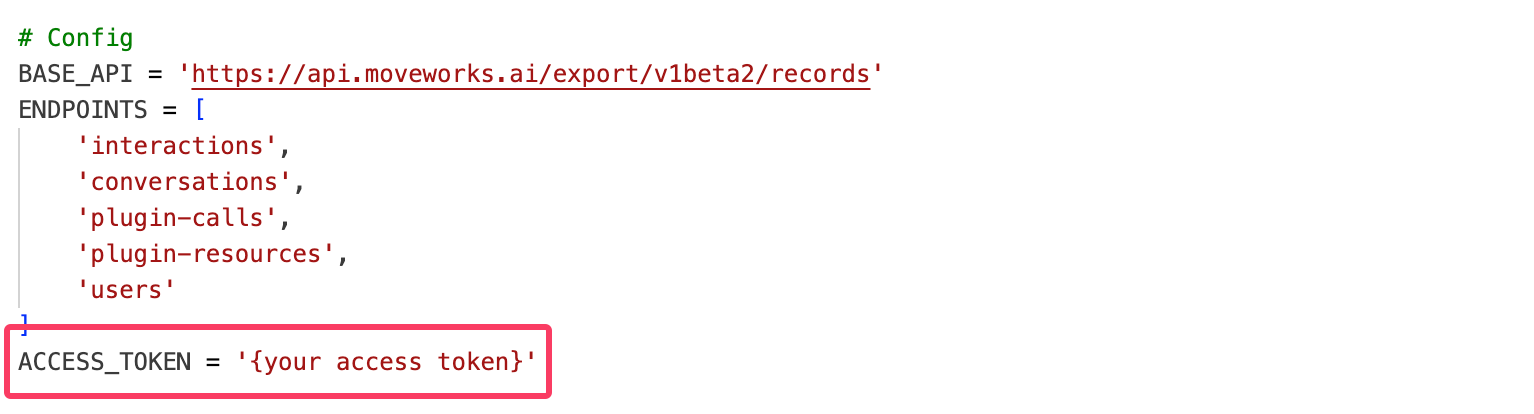
| 9 | # Config |
| 10 | BASE_API = 'https://api.moveworks.ai/export/v1beta2/records' |
| 11 | ENDPOINTS = [ |
| 12 | 'interactions', |
| 13 | 'conversations', |
| 14 | 'plugin-calls', |
| 15 | 'plugin-resources', |
| 16 | 'users' |
| 17 | ] |
| 18 | ACCESS_TOKEN = '<Access Token>' # Replace this |
| 19 | |
| 20 | # Time filter will be set dynamically based on user input |
| 21 | |
| 22 | # Setup logging |
| 23 | logging.basicConfig(level=logging.INFO, format='%(asctime)s - %(levelname)s - %(message)s') |
| 24 | |
| 25 | # Headers |
| 26 | headers = { |
| 27 | 'Authorization': f'Bearer {ACCESS_TOKEN}', |
| 28 | } |
| 29 | |
| 30 | # Retry config |
| 31 | MAX_RETRIES = 5 |
| 32 | |
| 33 | def get_user_date_inputs(): |
| 34 | """Get start and end dates from user input and convert to timestamp format""" |
| 35 | print("\n" + "="*50) |
| 36 | print("RAW INTERACTIONS TABLE BUILDER") |
| 37 | print("="*50) |
| 38 | print("Enter the date range for data extraction:") |
| 39 | print("Date format: YYYY-MM-DD (e.g., 2025-07-15)") |
| 40 | print("-"*50) |
| 41 | |
| 42 | while True: |
| 43 | try: |
| 44 | start_date_str = input("Enter start date (YYYY-MM-DD): ").strip() |
| 45 | start_date = datetime.strptime(start_date_str, "%Y-%m-%d") |
| 46 | break |
| 47 | except ValueError: |
| 48 | print("❌ Invalid date format. Please use YYYY-MM-DD format (e.g., 2025-07-15)") |
| 49 | |
| 50 | while True: |
| 51 | try: |
| 52 | end_date_str = input("Enter end date (YYYY-MM-DD): ").strip() |
| 53 | end_date = datetime.strptime(end_date_str, "%Y-%m-%d") |
| 54 | |
| 55 | if end_date < start_date: |
| 56 | print("❌ End date cannot be earlier than start date. Please try again.") |
| 57 | continue |
| 58 | break |
| 59 | except ValueError: |
| 60 | print("❌ Invalid date format. Please use YYYY-MM-DD format (e.g., 2025-07-15)") |
| 61 | |
| 62 | # Convert to timestamp format for API |
| 63 | start_timestamp = start_date.strftime("%Y-%m-%dT00:00:00.000Z") |
| 64 | # For end date, set to end of day |
| 65 | end_timestamp = (end_date + timedelta(days=1) - timedelta(microseconds=1)).strftime("%Y-%m-%dT23:59:59.999Z") |
| 66 | |
| 67 | time_filter = f"last_updated_time ge '{start_timestamp}' and last_updated_time le '{end_timestamp}'" |
| 68 | |
| 69 | print(f"\n✅ Date range set:") |
| 70 | print(f" Start: {start_date_str} 00:00:00 UTC") |
| 71 | print(f" End: {end_date_str} 23:59:59 UTC") |
| 72 | print(f" Filter: {time_filter}") |
| 73 | print("-"*50) |
| 74 | |
| 75 | return time_filter, start_date_str, end_date_str |
| 76 | |
| 77 | def clean_illegal_chars(df): |
| 78 | """Clean illegal characters from DataFrame""" |
| 79 | def remove_illegal_chars(value): |
| 80 | if isinstance(value, str): |
| 81 | return re.sub(r'[\x00-\x08\x0B\x0C\x0E-\x1F]', '', value) |
| 82 | return value |
| 83 | return df.applymap(remove_illegal_chars) |
| 84 | |
| 85 | def flatten_record(record): |
| 86 | """Flatten nested fields in record""" |
| 87 | flat = record.copy() |
| 88 | if isinstance(flat.get("detail"), dict): |
| 89 | detail = flat.pop("detail", {}) or {} |
| 90 | for key, value in detail.items(): |
| 91 | if isinstance(value, list): |
| 92 | value = ','.join(map(str, value)) |
| 93 | flat[f'detail_{key}'] = value |
| 94 | return flat |
| 95 | |
| 96 | def fetch_data(endpoint, time_filter): # Added time_filter parameter |
| 97 | """Fetch data from a specific endpoint""" |
| 98 | url = f'{BASE_API}/{endpoint}' |
| 99 | params = { |
| 100 | '$orderby': 'id desc', |
| 101 | '$filter': time_filter, # Using the passed time_filter |
| 102 | } |
| 103 | |
| 104 | data = [] |
| 105 | retries = 0 |
| 106 | page_count = 0 |
| 107 | |
| 108 | logging.info(f"Fetching data from /{endpoint}") |
| 109 | |
| 110 | while url: |
| 111 | try: |
| 112 | logging.info(f"Requesting page {page_count + 1}: {url}") |
| 113 | response = requests.get(url, headers=headers, params=params if url.endswith(endpoint) else None) |
| 114 | |
| 115 | if response.status_code == 200: |
| 116 | json_resp = response.json() |
| 117 | page_data = json_resp.get('value', []) |
| 118 | logging.info(f"Retrieved {len(page_data)} records from page {page_count + 1}") |
| 119 | |
| 120 | if not page_data: |
| 121 | break |
| 122 | |
| 123 | for record in page_data: |
| 124 | data.append(flatten_record(record)) |
| 125 | |
| 126 | url = json_resp.get('@odata.nextLink') |
| 127 | retries = 0 |
| 128 | page_count += 1 |
| 129 | |
| 130 | if endpoint == 'users': |
| 131 | time.sleep(2) |
| 132 | |
| 133 | elif response.status_code == 429: |
| 134 | wait = 90 if endpoint == 'users' else 60 |
| 135 | logging.warning(f"Rate limited on /{endpoint}. Waiting for {wait} seconds.") |
| 136 | time.sleep(wait) |
| 137 | |
| 138 | elif response.status_code in (500, 502, 503, 504): |
| 139 | if retries < MAX_RETRIES: |
| 140 | wait = 2 ** retries |
| 141 | logging.warning(f"Transient error {response.status_code} on /{endpoint}. Retrying in {wait} seconds...") |
| 142 | time.sleep(wait) |
| 143 | retries += 1 |
| 144 | else: |
| 145 | logging.error(f"Max retries reached on /{endpoint}. Aborting.") |
| 146 | break |
| 147 | |
| 148 | else: |
| 149 | logging.error(f"Unexpected error {response.status_code} on /{endpoint}: {response.text}") |
| 150 | break |
| 151 | |
| 152 | except Exception as e: |
| 153 | logging.exception(f"Exception occurred while calling /{endpoint}") |
| 154 | break |
| 155 | |
| 156 | if data: |
| 157 | df = pd.DataFrame(data) |
| 158 | df = clean_illegal_chars(df) |
| 159 | logging.info(f"Ingestion complete for /{endpoint}, {len(df)} records.") |
| 160 | return df |
| 161 | else: |
| 162 | logging.info(f"No data retrieved from /{endpoint}.") |
| 163 | return pd.DataFrame() |
| 164 | |
| 165 | def get_conversation_topics(interactions_df, conversation_id): |
| 166 | """Get all entities for a conversation ID""" |
| 167 | entities = interactions_df[interactions_df['conversation_id'] == conversation_id]['detail_entity'].dropna().unique() |
| 168 | return ', '.join([str(e) for e in entities if str(e) != 'nan']) |
| 169 | |
| 170 | def get_interaction_content(row, interactions_df): |
| 171 | """Extract interaction content from detail fields""" |
| 172 | interaction_id = row['id'] |
| 173 | interaction_row = interactions_df[interactions_df['id'] == interaction_id] |
| 174 | |
| 175 | if interaction_row.empty: |
| 176 | return "" |
| 177 | |
| 178 | interaction_row = interaction_row.iloc[0] |
| 179 | |
| 180 | # Based on API example, only use fields that actually exist |
| 181 | # From the example: detail.content is the main field for user message content |
| 182 | if 'detail_content' in interaction_row and pd.notna(interaction_row['detail_content']) and str(interaction_row['detail_content']) != '': |
| 183 | return str(interaction_row['detail_content']) |
| 184 | |
| 185 | return "" |
| 186 | |
| 187 | def get_bot_response(row, interactions_df): |
| 188 | """Get bot response using parent interaction ID""" |
| 189 | interaction_id = row['id'] |
| 190 | |
| 191 | # Find bot interactions with this interaction as parent |
| 192 | bot_response = interactions_df[ |
| 193 | (interactions_df['parent_interaction_id'] == interaction_id) & |
| 194 | (interactions_df['actor'] == 'bot') |
| 195 | ] |
| 196 | |
| 197 | if not bot_response.empty: |
| 198 | bot_row = bot_response.iloc[0] |
| 199 | # Only use the content field that actually exists in the API |
| 200 | if 'detail_content' in bot_row and pd.notna(bot_row['detail_content']) and str(bot_row['detail_content']) != '': |
| 201 | return str(bot_row['detail_content']) |
| 202 | |
| 203 | return "" |
| 204 | |
| 205 | def get_plugin_info(interaction_id, plugin_calls_df, plugin_type): |
| 206 | """Get plugin information based on type (unsuccessful, served, used)""" |
| 207 | if plugin_calls_df.empty: |
| 208 | return "" |
| 209 | |
| 210 | interaction_plugins = plugin_calls_df[plugin_calls_df['interaction_id'] == interaction_id] |
| 211 | |
| 212 | if interaction_plugins.empty: |
| 213 | return "" |
| 214 | |
| 215 | if plugin_type == 'unsuccessful': |
| 216 | # Plugins that were not served and not used |
| 217 | plugins = interaction_plugins[ |
| 218 | (interaction_plugins['served'] == False) & |
| 219 | (interaction_plugins['used'] == False) |
| 220 | ]['plugin_name'].unique() |
| 221 | elif plugin_type == 'served': |
| 222 | # Plugins that were served |
| 223 | plugins = interaction_plugins[ |
| 224 | interaction_plugins['served'] == True |
| 225 | ]['plugin_name'].unique() |
| 226 | elif plugin_type == 'used': |
| 227 | # Plugins that were served and used |
| 228 | plugins = interaction_plugins[ |
| 229 | (interaction_plugins['served'] == True) & |
| 230 | (interaction_plugins['used'] == True) |
| 231 | ]['plugin_name'].unique() |
| 232 | else: |
| 233 | return "" |
| 234 | |
| 235 | return ', '.join([str(p) for p in plugins if str(p) != 'nan']) |
| 236 | |
| 237 | def get_resource_info(interaction_id, plugin_resources_df, info_type): |
| 238 | """Get resource information (domain, citations, content items, tickets)""" |
| 239 | if plugin_resources_df.empty: |
| 240 | return "" if info_type != 'citation_count' else 0 |
| 241 | |
| 242 | interaction_resources = plugin_resources_df[plugin_resources_df['interaction_id'] == interaction_id] |
| 243 | |
| 244 | if interaction_resources.empty: |
| 245 | return "" if info_type != 'citation_count' else 0 |
| 246 | |
| 247 | if info_type == 'domain': |
| 248 | domains = interaction_resources['detail_domain'].dropna().unique() |
| 249 | return ', '.join([str(d) for d in domains if str(d) != 'nan']) |
| 250 | |
| 251 | elif info_type == 'citation_count': |
| 252 | unique_resources = interaction_resources['resource_id'].dropna().nunique() |
| 253 | return unique_resources |
| 254 | |
| 255 | elif info_type == 'content_item_id': |
| 256 | # Use external_resource_id from detail field |
| 257 | content_ids = interaction_resources['detail_external_resource_id'].dropna().unique() |
| 258 | return ', '.join([str(c) for c in content_ids if str(c) != 'nan']) |
| 259 | |
| 260 | elif info_type == 'content_item_name': |
| 261 | content_names = interaction_resources['detail_name'].dropna().unique() |
| 262 | return ', '.join([str(c) for c in content_names if str(c) != 'nan']) |
| 263 | |
| 264 | elif info_type == 'ticket_type': |
| 265 | # Need to determine ticket type logic based on your business rules |
| 266 | # This might need adjustment based on how you determine user vs bot initiated |
| 267 | ticket_resources = interaction_resources[ticket_resources['type'] == 'RESOURCE_TYPE_TICKET'] |
| 268 | if not ticket_resources.empty: |
| 269 | return "user initiated ticket" # Default, adjust logic as needed |
| 270 | return "" |
| 271 | |
| 272 | elif info_type == 'ticket_id': |
| 273 | ticket_resources = interaction_resources[interaction_resources['type'] == 'RESOURCE_TYPE_TICKET'] |
| 274 | ticket_ids = ticket_resources['detail_external_resource_id'].dropna().unique() |
| 275 | return ', '.join([str(t) for t in ticket_ids if str(t) != 'nan']) |
| 276 | |
| 277 | return "" |
| 278 | |
| 279 | def get_interaction_surface(interaction_id, interactions_df): |
| 280 | """Get the platform/surface where interaction took place""" |
| 281 | interaction_row = interactions_df[interactions_df['id'] == interaction_id] |
| 282 | |
| 283 | if not interaction_row.empty: |
| 284 | # Use 'platform' field from the API response |
| 285 | surface = interaction_row.iloc[0].get('platform', '') |
| 286 | return str(surface) if pd.notna(surface) else "" |
| 287 | |
| 288 | return "" |
| 289 | |
| 290 | def get_user_language(user_id, users_df): |
| 291 | """Get user's preferred language""" |
| 292 | if users_df.empty: |
| 293 | return "" |
| 294 | |
| 295 | # Use the actual field name from API response |
| 296 | user_row = users_df[users_df['id'] == user_id] |
| 297 | |
| 298 | if not user_row.empty: |
| 299 | language = user_row.iloc[0].get('user_preferred_language', '') |
| 300 | return str(language) if pd.notna(language) else "" |
| 301 | |
| 302 | return "" |
| 303 | |
| 304 | def build_raw_interactions_table(all_dataframes): |
| 305 | """Build the final raw interactions table""" |
| 306 | logging.info("Building raw interactions table...") |
| 307 | |
| 308 | # Extract dataframes |
| 309 | interactions_df = all_dataframes.get('interactions', pd.DataFrame()) |
| 310 | conversations_df = all_dataframes.get('conversations', pd.DataFrame()) |
| 311 | plugin_calls_df = all_dataframes.get('plugin-calls', pd.DataFrame()) |
| 312 | plugin_resources_df = all_dataframes.get('plugin-resources', pd.DataFrame()) |
| 313 | users_df = all_dataframes.get('users', pd.DataFrame()) |
| 314 | |
| 315 | if interactions_df.empty: |
| 316 | logging.error("No interactions data available") |
| 317 | return pd.DataFrame() |
| 318 | |
| 319 | # Filter for user-led interactions only |
| 320 | user_interactions = interactions_df[interactions_df['actor'] == 'user'].copy() |
| 321 | |
| 322 | if user_interactions.empty: |
| 323 | logging.warning("No user interactions found") |
| 324 | return pd.DataFrame() |
| 325 | |
| 326 | logging.info(f"Processing {len(user_interactions)} user interactions...") |
| 327 | |
| 328 | # Initialize the raw interactions table |
| 329 | raw_interactions = pd.DataFrame() |
| 330 | |
| 331 | # Base columns from interactions |
| 332 | raw_interactions['Timestamp'] = user_interactions['created_time'] |
| 333 | raw_interactions['Conversation ID'] = user_interactions['conversation_id'] |
| 334 | raw_interactions['Interaction ID'] = user_interactions['id'] |
| 335 | raw_interactions['Interaction Type'] = user_interactions['type'] # Changed from 'interaction_type' |
| 336 | |
| 337 | # Get conversation domain from conversations table |
| 338 | if not conversations_df.empty: |
| 339 | conversation_domain_map = conversations_df.set_index('id')['primary_domain'].to_dict() # Changed from 'domain' |
| 340 | raw_interactions['Conversation Domain'] = raw_interactions['Conversation ID'].map(conversation_domain_map) |
| 341 | else: |
| 342 | raw_interactions['Conversation Domain'] = "" |
| 343 | |
| 344 | # Get conversation topics (aggregated for each conversation) |
| 345 | logging.info("Processing conversation entities...") |
| 346 | raw_interactions['Conversation Topic'] = raw_interactions['Conversation ID'].apply( |
| 347 | lambda x: get_conversation_topics(interactions_df, x) |
| 348 | ) |
| 349 | |
| 350 | # Get interaction content and bot response |
| 351 | logging.info("Processing interaction content and bot responses...") |
| 352 | raw_interactions['Interaction Content'] = user_interactions.apply( |
| 353 | lambda row: get_interaction_content(row, interactions_df), axis=1 |
| 354 | ) |
| 355 | |
| 356 | raw_interactions['Bot Response'] = user_interactions.apply( |
| 357 | lambda row: get_bot_response(row, interactions_df), axis=1 |
| 358 | ) |
| 359 | |
| 360 | # Get plugin information |
| 361 | logging.info("Processing plugin information...") |
| 362 | raw_interactions['Unsuccessful Plugins'] = raw_interactions['Interaction ID'].apply( |
| 363 | lambda x: get_plugin_info(x, plugin_calls_df, 'unsuccessful') |
| 364 | ) |
| 365 | |
| 366 | raw_interactions['Plugin Served'] = raw_interactions['Interaction ID'].apply( |
| 367 | lambda x: get_plugin_info(x, plugin_calls_df, 'served') |
| 368 | ) |
| 369 | |
| 370 | raw_interactions['Plugin Used'] = raw_interactions['Interaction ID'].apply( |
| 371 | lambda x: get_plugin_info(x, plugin_calls_df, 'used') |
| 372 | ) |
| 373 | |
| 374 | # Get resource information |
| 375 | logging.info("Processing resource information...") |
| 376 | raw_interactions['Resource Domain'] = raw_interactions['Interaction ID'].apply( |
| 377 | lambda x: get_resource_info(x, plugin_resources_df, 'domain') |
| 378 | ) |
| 379 | |
| 380 | raw_interactions['No of Citations'] = raw_interactions['Interaction ID'].apply( |
| 381 | lambda x: get_resource_info(x, plugin_resources_df, 'citation_count') |
| 382 | ) |
| 383 | |
| 384 | raw_interactions['Content Item Name'] = raw_interactions['Interaction ID'].apply( |
| 385 | lambda x: get_resource_info(x, plugin_resources_df, 'content_item_name') |
| 386 | ) |
| 387 | |
| 388 | raw_interactions['Content Item ID'] = raw_interactions['Interaction ID'].apply( |
| 389 | lambda x: get_resource_info(x, plugin_resources_df, 'content_item_id') |
| 390 | ) |
| 391 | |
| 392 | raw_interactions['Ticket Type'] = raw_interactions['Interaction ID'].apply( |
| 393 | lambda x: get_resource_info(x, plugin_resources_df, 'ticket_type') |
| 394 | ) |
| 395 | |
| 396 | raw_interactions['Ticket ID'] = raw_interactions['Interaction ID'].apply( |
| 397 | lambda x: get_resource_info(x, plugin_resources_df, 'ticket_id') |
| 398 | ) |
| 399 | |
| 400 | # Get interaction surface |
| 401 | raw_interactions['Interaction Surface'] = raw_interactions['Interaction ID'].apply( |
| 402 | lambda x: get_interaction_surface(x, interactions_df) |
| 403 | ) |
| 404 | |
| 405 | # Get user information |
| 406 | if 'user_id' in user_interactions.columns: |
| 407 | logging.info("Processing user information...") |
| 408 | raw_interactions['User Preferred Language'] = user_interactions['user_id'].apply( |
| 409 | lambda x: get_user_language(x, users_df) |
| 410 | ) |
| 411 | else: |
| 412 | raw_interactions['User Preferred Language'] = "" |
| 413 | |
| 414 | # Add placeholder columns for external user data |
| 415 | raw_interactions['User Department'] = "" # To be populated from external identity system |
| 416 | raw_interactions['User Location'] = "" # To be populated from external identity system |
| 417 | raw_interactions['User Country'] = "" # To be populated from external identity system |
| 418 | |
| 419 | logging.info(f"Raw interactions table built with {len(raw_interactions)} rows and {len(raw_interactions.columns)} columns") |
| 420 | |
| 421 | return raw_interactions |
| 422 | |
| 423 | def main(): |
| 424 | """Main function to orchestrate the entire process""" |
| 425 | # Get user input for date range |
| 426 | time_filter, start_date_str, end_date_str = get_user_date_inputs() |
| 427 | |
| 428 | logging.info("Starting raw interactions table builder...") |
| 429 | |
| 430 | # Step 1: Fetch all data |
| 431 | all_dataframes = {} |
| 432 | |
| 433 | for endpoint in ENDPOINTS: |
| 434 | df = fetch_data(endpoint, time_filter) |
| 435 | if not df.empty: |
| 436 | all_dataframes[endpoint] = df |
| 437 | |
| 438 | if not all_dataframes: |
| 439 | logging.error("No data retrieved from any endpoint") |
| 440 | return |
| 441 | |
| 442 | # Step 2: Build raw interactions table |
| 443 | raw_interactions_table = build_raw_interactions_table(all_dataframes) |
| 444 | |
| 445 | if raw_interactions_table.empty: |
| 446 | logging.error("Failed to build raw interactions table") |
| 447 | return |
| 448 | |
| 449 | # Step 3: Save results |
| 450 | timestamp = datetime.now().strftime("%Y%m%d_%H%M%S") |
| 451 | |
| 452 | # Save raw data to Excel (optional) |
| 453 | raw_data_file = Path(f"moveworks_raw_data_{start_date_str}_to_{end_date_str}_{timestamp}.xlsx") |
| 454 | with pd.ExcelWriter(raw_data_file, engine='openynxl') as writer: |
| 455 | for endpoint, df in all_dataframes.items(): |
| 456 | sheet_name = endpoint[:31] # Excel sheet name max limit |
| 457 | df.to_excel(writer, sheet_name=sheet_name, index=False) |
| 458 | logging.info(f"Raw data saved to {raw_data_file}") |
| 459 | |
| 460 | # Save final raw interactions table |
| 461 | final_file = Path(f"raw_interactions_table_{start_date_str}_to_{end_date_str}_{timestamp}.xlsx") |
| 462 | raw_interactions_table.to_excel(final_file, index=False, sheet_name='Raw Interactions') |
| 463 | logging.info(f"Final raw interactions table saved to {final_file}") |
| 464 | |
| 465 | # Also save as CSV for easier processing |
| 466 | csv_file = Path(f"raw_interactions_table_{start_date_str}_to_{end_date_str}_{timestamp}.csv") |
| 467 | raw_interactions_table.to_csv(csv_file, index=False) |
| 468 | logging.info(f"Final raw interactions table saved to {csv_file}") |
| 469 | |
| 470 | # Print summary |
| 471 | print("\n" + "="*50) |
| 472 | print("RAW INTERACTIONS TABLE SUMMARY") |
| 473 | print("="*50) |
| 474 | print(f"Total interactions processed: {len(raw_interactions_table)}") |
| 475 | print(f"Date range: {start_date_str} to {end_date_str}") |
| 476 | print(f"Time filter: {time_filter}") |
| 477 | print(f"Columns: {list(raw_interactions_table.columns)}") |
| 478 | print(f"Files generated:") |
| 479 | print(f" - {raw_data_file} (raw data)") |
| 480 | print(f" - {final_file} (final table - Excel)") |
| 481 | print(f" - {csv_file} (final table - CSV)") |
| 482 | |
| 483 | # Show sample data |
| 484 | if len(raw_interactions_table) > 0: |
| 485 | print(f"\nSample data (first 3 rows):") |
| 486 | print(raw_interactions_table.head(3).to_string()) |
| 487 | |
| 488 | if __name__ == "__main__": |
| 489 | main() |